【学习笔记】好文分享
多看多想多记有意思的东西,不定时更新。
希望大家能多关注、支持一下原作者,我只是一个小偷到处偷别人的理解。
1. 归一化
归一化的解释:知乎文章
note:以二元回归问题为例,损失函数 J 的自变量是模型的参数w,表征的是在给定数据(x_1, x_2, y)情况下,不同参数w对损失(即预测值与真实值之间的差距)的影响。如果不使用归一化,x_1与x_2值直接取实际的分布范围,两者的分布往往有比较大的差距,做出的损失函数图像对应的等高线就会是一个椭圆。 而椭圆优化到最优点需要走好多步,且对学习率的调整更为严格,而圆的优化就相对简单很多,如下图所示:
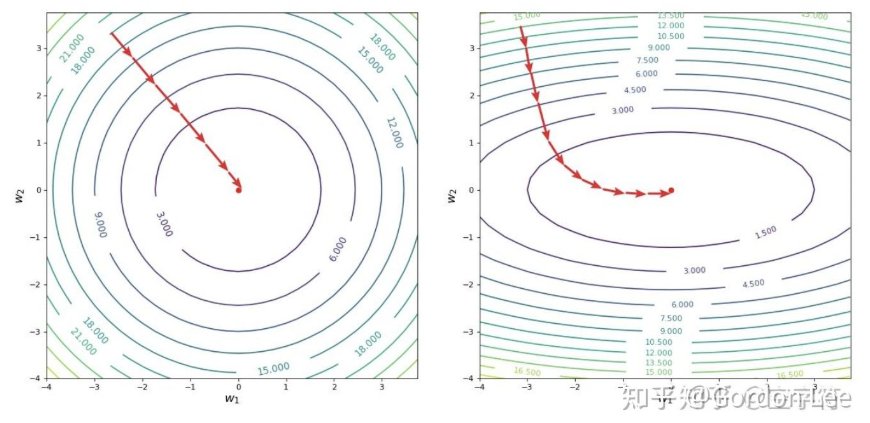
另一个解释归一化就是神经网络中,不同层之间的分布如果不能确定下来,那么训练过程中,前一个层的参数变化会导致后面层所接受到的输入的分布发生巨大的变化,进而导致之后所有层的学习受到很大的影响。从拟合的角度来看,每一层想要很好地work的话,他所能够处理的input往往是处于一定的分布之内的。例如0点处的泰勒展开,对于0点附近的点有比较好的拟合效果,但对于远离0点的数字往往就与真实函数值偏差过大。
总结上述俩者的理论,归一化是为了保证:【1】输入的多个变量x_1, x_2等应该保持尽可能相似的“小分布” 。这一点可以帮助我们审视不同的norm是否合理。【2】每一层的输出都最好能保持固定的“小分布”。这一点只要保证每一层之后都用到相同的norm方式应该就能保证。另外还需关注的点——激活函数也可能会影响数据的分布,需要选择保证数值稳定性的激活函数。 卷积神经网络中的Channel对应的实际上对应的是序列模型中的d_model or hidden_size;卷积神经网络中的(Height, Width)对应的其实是序列模型的Squence_length(一般用N)
2. 位置编码:ROPE & YARN
探秘Transformer系列之(23)— 长度外推 - 罗西的思考 - 博客园
2.1 绝对位置编码(APE)
Transformer本身并不能区分不同位置的输入,需要人为添加位置编码(Positional Encoding, PE)来使得模型能区分的出不同的位置,因为语序会影响语义。我们希望位置编码在能让模型学习到不同位置的表征的情况下,还能提高模型的外推能力。由于训练的时候往往难以训练长文本(显存资源消耗过多、优质长文本数据较少),可实际推理的时候往往需要输出长文本,因此我们期望模型具备外推能力,即训练的时候在短文本里训练,而锻炼模型在推理长文本输出能力。 最初的Transformer使用的是正弦绝对位置编码(正弦APE),表现为在向量化之后,注意力计算之前,就对输入的token加上一个用绝对位置信息表征的分量PE。即$x’=x+PE$ 这里的PE计算公式如下所示: $$PE(m,2i)=sin(\frac{m*\theta}{10000^{\frac{2i}{D}}}); PE(m,2i+1)=cos(\frac{m*\theta}{10000^{\frac{2i}{D}}})$$
其中m代表token的位置,2i与2i+1分别是隐藏层(feature)在奇偶情况下的不同表征。以输入的(batch, sequence_length or n , d_model or hidden_size)为例,m对应的就是其中的sequence_length, 2i与2i+1对应的则是d_model。 绝对位置编码的好处是可兼容各种不同的注意力,处理过程是在注意力计算之前;但缺点是外推能力不足,遇到没见过的位置编码时表现很差。同时,在处理相对位置信息时,模型会更为吃力。在注意力计算中,位置编码信息通过注意力计算中的点乘来发挥作用的。采用正弦绝对编码方式的结果无法提现相对位置的关系,如下所示:
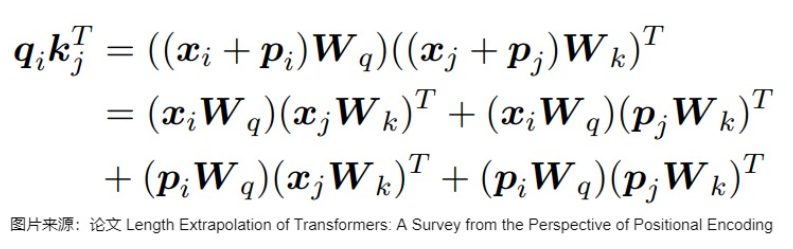
由此可见绝对位置编码的外推能力很弱,无法满足人们对长下文的追求。
2.2 ROPE
ROPE是一种流行的相对位置编码,相对位置编码天然的具备平移不变性,使得外推更为容易。具体而言,ROPE不采取加法方式添加位置信息,而是用旋转矩阵来处理注意力机制中的q和k,结果相当于将q和k向量旋转一个角度,故被称作旋转位置编码:
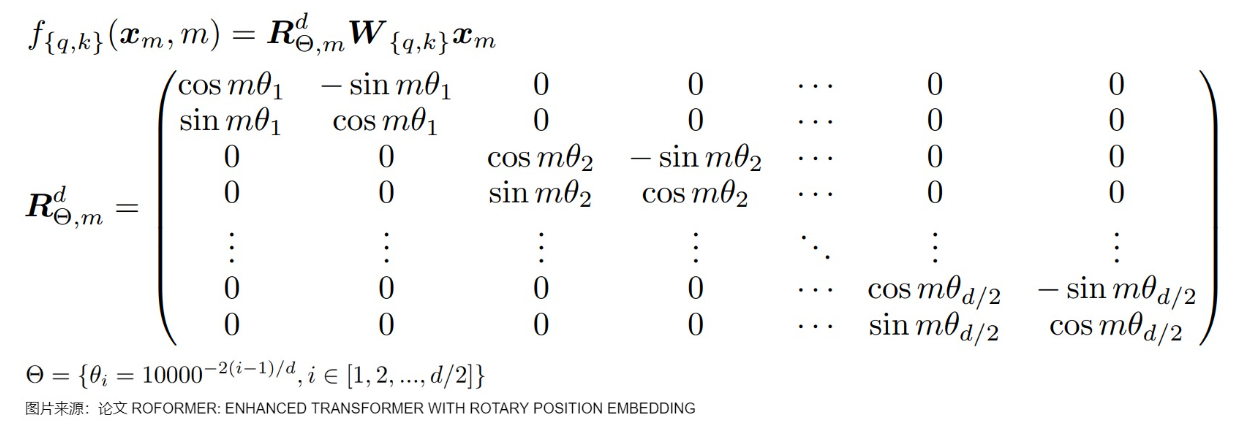
上图中的m表示位置,$\theta$ 在不同维度(d_model)中取得不同的大小,$\theta_i=10000^{\frac{-2i}{D}}$,这里的 i 从零开始更为简洁,等效于上图中的从1开始。上述的处理就相当于把d分为d/2组二维向量,每组二维向量都旋转$m\theta_i$度。
不同维度对应不同的旋转角度,其中低维度对应的旋转角度大,相当于旋转的角速度大,频率高,波长短,更有利于捕捉相近token之间的关系;高维度对应的旋转角度小,相当于角速度小,频率低,波长长,更有利于捕捉大范围token关系。 但ROPE的外推能力依旧较弱,模型难以处理没见过长序列位置编码,仍需要其他外推方法的处理。特别是高维度低频区间,可能在一整个训练周期都”转不了一圈“,训练效果较差。
2.3 外推–YARN
YARN是一种外推手段,在讨论他之前先看看其他外推方案。
首先是线性插值,直接把位置m改为$m\frac{L}{L’}$带入公式进行计算,其中L’是推理时的上下文长度,L是训练时的上下文长度。这种做法简单粗暴,但对于低维度高频率区域,容易会损失近距离依赖。
然后是NTK-Aware Interpolation,则是把原有的$\theta_i=b^{\frac{-2i}{D}}$(其中b取10000就是先前的ROPE)改为了$\theta_i=b^{\frac{-2i}{D}}*s^{\frac{-2i}{D}}$,此时对于低维度高频率就相当于更频繁的插值,对于高维度低频率则插值不明显。这样更好地均衡了高维与低维的表征。
进一步是Dynamic Scaling, $\theta_i=b^{\frac{-2i}{D}}*(as-a+1)^{\frac{-2i}{D}}$。a,b需要满足 a(d/2)b=log k,且 b 的推荐范围为 [0.625,0.75]。这个好变态没太看懂。
NTK-by-parts Interpolation就是直接按照波长($\lambda_d=\frac{2\pi}{\theta_d}$,其中$\theta_d$就是最原始的$\theta$)做了分段函数。

最后的YaRN是基于NTK-aware方法的进一步拓展,也就是YaRN=注意力温度缩放+NTK-by-parts。它核心解决的问题是线性内插导致的self-attention 点积的值增大。由于线性内插会改变旋转向量转动的幅度,原来距离较远的q,k点积由于旋转幅度变小,他们的点积结果会增大,进而导致Softmax操作过于“锐化”,使得注意力分布集中于少数位置,削弱模型对全局上下文的关注能力。实际上就相当于Temperature,在注意力计算后,softmax之前对结果统一缩小,使得注意力更平均。